Building an Agentic AI Platform with SAFe: What Worked, What Didn't
When Generative AI or Large Language Models (LLMs) started to attract attention in our company, I was tasked to setup a Generative AI Platform team. The mandate was to build a platform that can be used by other internal teams to build AI-powered applications. Specific tasks to be done include: LLMs deployment, API and user governance, monitoring, and incidence response etc. As the team manager and a part-time SAFe Practice Consultant, we tried to follow the best practices of SAFe.
As the technology and our organization evolved, we are now scaling our platform to support agentic AI applications. It’s a new challenge for the teams. And I thought it’s a good time to reflect and share my thoughts and experiences with the community.
Why do we need a Platform?
Platform (noun): A foundation that others build upon. In software, it’s a set of shared capabilities—infrastructure, tools, APIs—that enable teams to deliver faster without reinventing the wheel.
Benefits of having a platform to the organization:
- Reduces cognitive load for product teams
- Provides “paved roads” (opinionated paths) while allowing innovation
- Treated as a product with internal customers
- Measured by adoption and developer satisfaction, not just uptime
- e.g. google cloud platform allows you to deploy your application in cloud with few clicks
What does an Agentic AI Platform look like?
In less than 10 years, the industry has evolved from Machine Learning (ML) to Generative AI (GenAI) and now to Agentic AI.
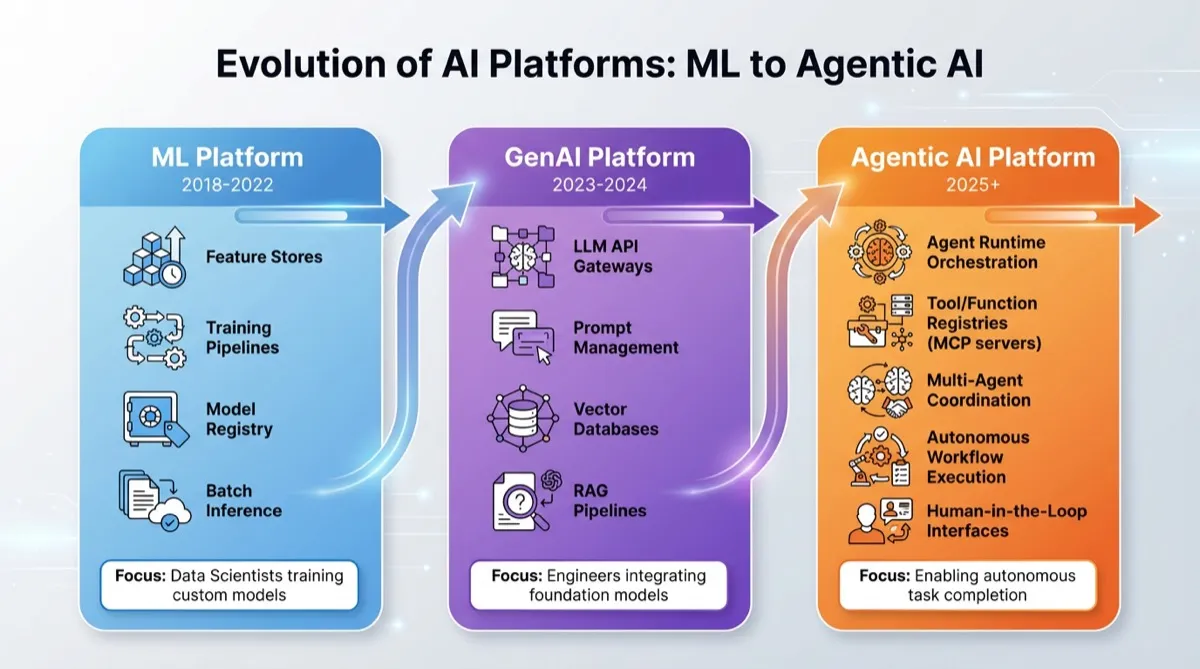
It feels like we haven’t even understood GenAI, and it has already evolved to Agentic AI.
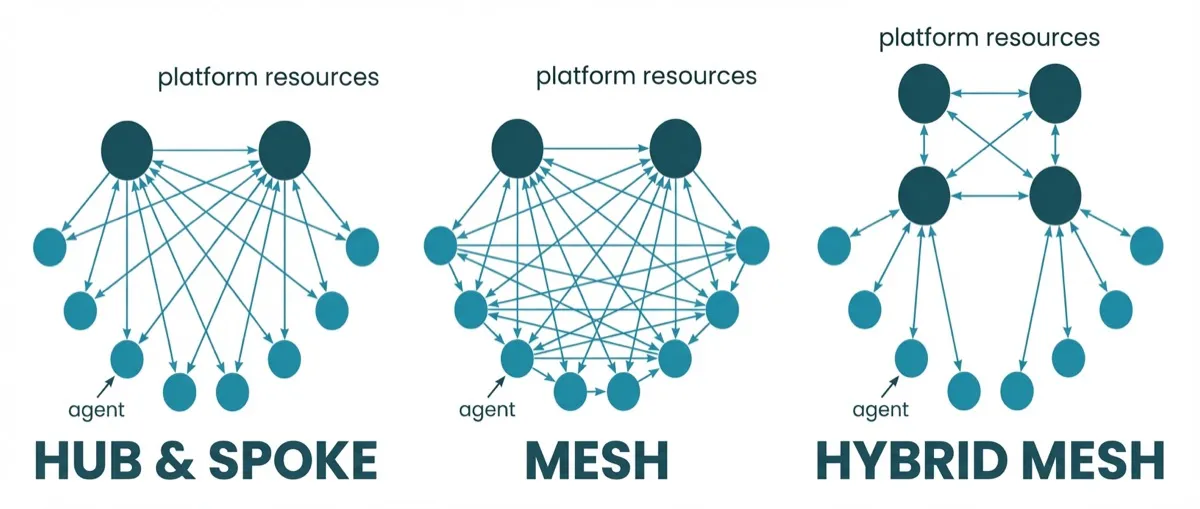
I like to simply think about agentic AI as a cluster of GenAI agents working together to do something autonomously. When there are a few standalone GenAI applications (agents), they may share some common capabilities or platform resources, such as LLM inference, vector database, etc. They form a hub topology where the hub is the platform and the spokes are the agents.
When there are many of them working in a coordinated way, they form a mesh topology. And the complexity of managing them grows exponentially. Besides agents, there are tools (e.g. MCP servers) that agents can use in a many-to-many fashion. In more complex scenarios, we may have a hybrid mesh topology, where platform resources needs to be connected, e.g. LLMs and vector databases.
What should an Agentic AI Platform provide?
Technically, there are four layers of an agentic AI platform:
- Foundation Layer
- Agent-Specific Layer
- Operational Layer
- Developer Experience Layer
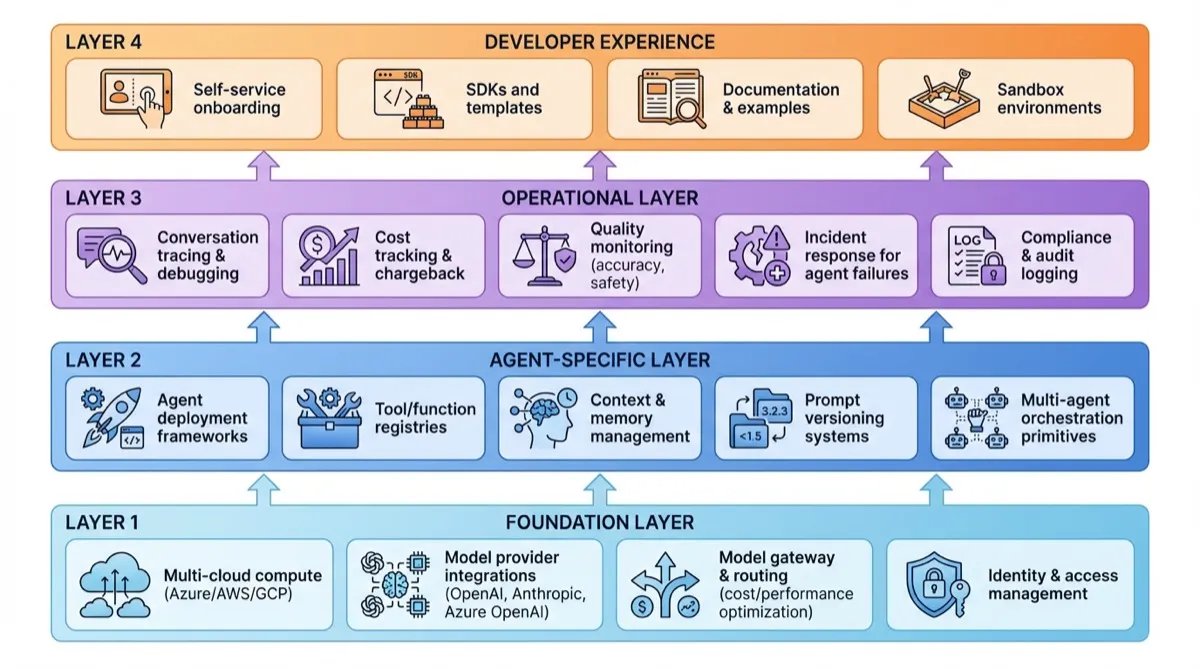
Agentic AI platform vs. GenAI platform: We’re not just providing infrastructure - we’re enabling autonomous decision-making systems. The shift from ‘provide model endpoints’ to ‘enable autonomous agents’ introduces new concerns: behavioral safety, explainability, governance of what agents can do.
SAFe and Platform Teams: The Foundation
A Brief Overview of SAFe
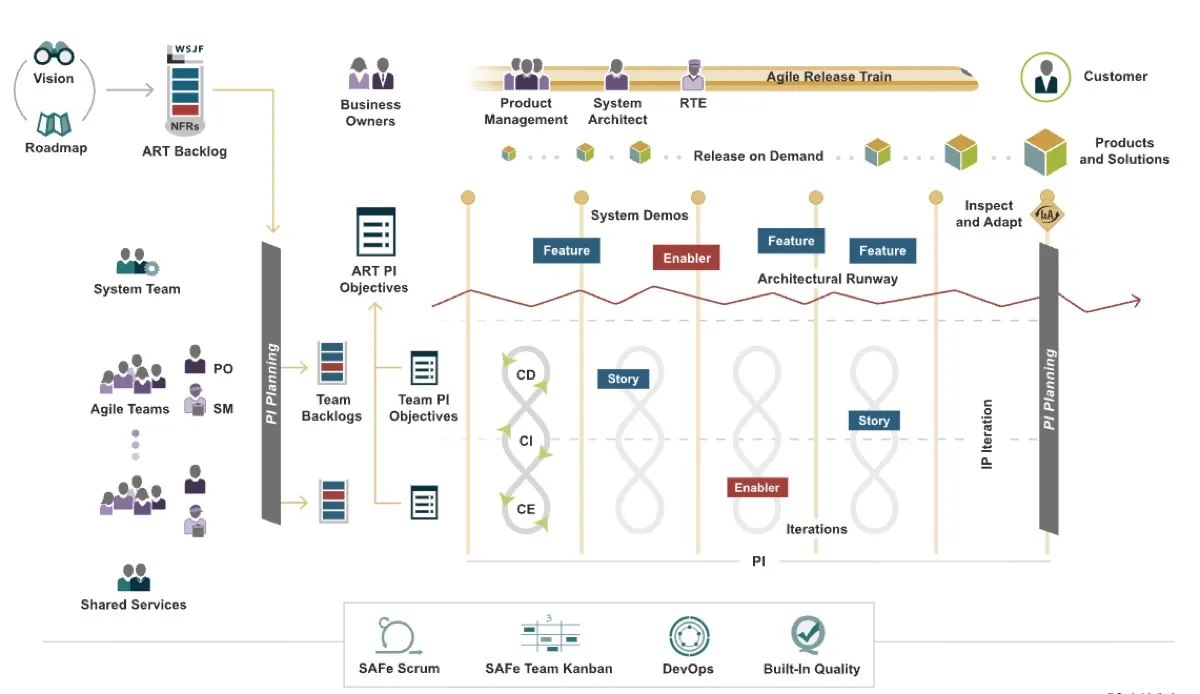
The Scaled Agile Framework (SAFe) solves a fundamental problem: how do you maintain agility with 50-500+ people working on interconnected products?
Core concepts:
- Agile Release Trains (ARTs): Teams of 50-125 people planning, developing, and delivering together on a synchronized cadence
- Program Increments (PIs): Fixed 8-12 week planning cycles where teams align on objectives and dependencies
- Built-In Quality: Quality practices (TDD, CI/CD, pairing) embedded in the development process, not inspected in later
- System Demos: Bi-weekly integrated demonstrations to stakeholders
SAFe balances autonomy (teams making local decisions quickly) with alignment (everyone moving toward common goals).
SAFe’s Guidance for Platform Teams
Platform teams (or “System Teams” in SAFe terminology) enable product teams by providing foundational capabilities. SAFe offers specific guidance:
Platform-as-a-Product
Your platform IS a product. Product teams are your customers.
What does it mean?:
- We have a Product Owner who prioritizes based on customer needs
- We measure customer satisfaction (NPS, adoption rates)
- We maintain a value-driven backlog, not just technical work
- We evolve based on feedback from internal customers
For example: Instead of focusing on “what technology is new”, we focus on “what will unblock product teams’ goals.” When we built our model gateway, we included SDKs, documentation, self-service onboarding, and sandbox environments—because we treated it as a product, not just infrastructure.
Architectural Runway
Build technical foundation ahead of demand spikes.
If we’d waited until demand spikes, we would have blocked many teams. Runway prevents this.
Allocate 30-50% of platform capacity to runway work vs. immediate requests.
Be Enablers, Not bottleneck
Platform teams should enable product teams, not become bottlenecks.
❌ Product team needs capability → Files ticket → Waits for platform → Platform builds it FOR them → Creates dependency
✅ Platform builds self-service capability → Product teams adopt when ready → Platform provides support but doesn’t gate decisions
The vision is a self-service portal where teams can create agent projects from templates, provision vector databases, deploy to dev/staging/production, and view cost dashboards. No tickets. No waiting. Just automated guardrails — cost limits, security policies, compliance checks.
In reality, we haven’t fully reached this stage. It is hard to not become a bottleneck when the technology is moving fast and demand from product teams is high. But every manual step we automate gets us closer. The goal is clear: if a team needs a capability, they should be able to adopt it without filing a ticket.
Synchronized Cadence
Platform teams participate in the same ART events as product teams:
PI Planning: Platform presents roadmap, product teams declare dependencies, conflicts surface early
System Demos: Platform demonstrates new capabilities, product teams show features built using platform
Inspect & Adapt: Joint retrospective on coordination effectiveness
We learned it the hard way that we should run on the same cadence as product teams. Initially, we ran on a separate cadence (“infrastructure has different timelines”). And we run a separate meeting to align with product teams. It was a mess. It would be better if we run on the same cadence as product teams. And we run a joint system demo.
Clear SLAs and Support Model
Treat your platform services like external SaaS providers.
This creates predictability. Product teams know what they can depend on.
Reusable Contribution Model
Product teams sometimes build capabilities that are reusable, and should be generalized
For example: Tool Registry where teams publish custom tools. If 2+ teams use it, we promote to platform-supported status.
Anti-Patterns to Avoid
Despite of the best intentions, platform teams often fall into these traps and we learn from them.
❌ The Ivory Tower Platform Team
Problem: Building what’s architecturally elegant without understanding customer needs.
Symptoms:
- Low adoption of platform features
- Product teams building their own solutions
- Roadmap driven by “emerging tech” not customer problems
Example: Built sophisticated prompt versioning with Git-like branching. Very impressive. Adoption: 1/8 teams. Why? Teams just wanted “save prompt, roll back if breaks.” We simplified to basic versioning + rollback, adoption jumped to 7/8 teams.
Remedy: Measure adoption as primary success metric. Talk to customers constantly.
❌ The Ticket Queue bottleneck
Problem: Product teams file tickets and wait for platform team to do work for them.
Symptoms:
- Platform has 50+ open tickets, 2+ week resolution time
- Product teams blocked on “simple” requests
- Platform team firefighting, never building strategically
Example: Teams filed tickets to “deploy my agent.” Manual review and deploy. Average: 3 days.
Remedy: Build self-service capabilities. Automate common requests.
❌ The Unstable Foundation
Problem: Shipping half-baked capabilities, frequently breaking APIs.
Symptoms:
- Product teams afraid to upgrade platform versions
- ”It worked yesterday, now it’s broken”
- No migration guides for breaking changes
Example: Platform team updated model gateway v1→v2 with breaking changes. Announced in PI Planning. Provided migration guide. Maintained v1 for full PI (12 weeks) while teams migrated.
Compare to our earlier mistake: “We updated the API yesterday, here’s new format, good luck!” Result: Three teams had outages.
Remedy: Breaking changes announced 1 PI ahead. Definition of Done includes documentation and migration guides.
❌ The "Not Our Problem" Platform
Problem: Ship capability and consider job done. No support, no documentation updates.
Symptoms:
- Features sit unused because too hard to adopt
- Teams build workarounds rather than use platform
- Platform team: “It works, read the docs”
Remedy:
- Office hours: Twice weekly for questions
- Embedded support: Platform engineer pairs with team first week of adoption
- Documentation loop: Every question asked 3+ times becomes doc update
- Success metric: ”% of teams successfully using within 2 weeks of release”
❌ Platform Team Does Work FOR Product Teams
Problem: Building product features instead of enabling teams to build them.
Symptoms:
- Platform backlog full of product-specific features
- Product teams waiting in queue for platform capacity
- No time for strategic infrastructure work
Boundary to enforce:
Platform builds:
- Model gateway, RAG framework, prompt versioning, cost tracking
Platform does NOT build:
- “Build the expense agent for Finance team”
Product teams build:
- Their expense agent, their knowledge base, their business logic
Remedy: Pair with product teams to show how to use agent framework. They build their agent. We review for security/best practices.
❌ Zero Runway / Always Reactive
Problem: Only working on immediate requests, never building ahead.
Symptoms:
- Product teams blocked because needed infrastructure doesn’t exist
- Platform always playing catch-up
- ”We’ll build that when you need it” → they need it now → scramble
Remedy: Reserve 30-50% capacity for strategic runway work.
For example: Platform Sprint Capacity
- 40%: Runway (building ahead)
- 30%: Product team support
- 20%: Operations (incidents, maintenance)
- 10%: Innovation/experimentation
Key Takeaways
From applying SAFe to our GenAI platform:
- Platform-as-product is non-negotiable. The moment you stop thinking about product teams as customers, you build the wrong things.
- Runway enables velocity. Building 1-2 PIs ahead creates faster product team velocity than being reactive.
- Self-service over approval. Every review board we created slowed teams without improving quality. Automated guardrails work better.
- Measure adoption, not deployment. Shipping a capability means nothing if teams don’t use it.
- Support is part of the product. The difference between adoption and abandonment often comes down to how easy it is to get help.
SAFe’s platform guidance is sound — it’s based on years of observing what works at scale. The core principles hold even as we move into GenAI and agentic AI.
How SAFe Adapts for AI
SAFe’s principles are sound. But the practices need adaptation when the technology moves faster than any planning cadence. Four areas where we’ve had to evolve.
Runway when the ground is moving
Traditional architectural runway means building 1-2 PIs ahead with confidence. You know what product teams will need because the technology landscape is stable. Cloud services, databases, APIs — they evolve, but predictably.
GenAI runway is different. What you build today may be obsolete before teams consume it. A new model drops. A new protocol emerges. A framework you evaluated last month now does what your custom code does.
The adaptation: invest in interfaces and abstractions, not implementations. Build thin wrappers. Design every component to be replaceable.
Have a small group of “scouts” who are responsible for tracking emerging tech weekly and briefing the team. Not a full-time job. A rotating responsibility. The intel are shared with the team and it could affect our roadmap.
PI planning should includes exploration spikes — timeboxed investigations into emerging capabilities. E.g. “Spend 3 days evaluating framework X” could be a valid PI objective. Even though not committed.
In GenAI, runway means building things designed to be replaced. The best platform code is code you can delete without breaking anything. The technical unpredictability driving this adaptation is covered in New Challenges.
Structured experimentation
The 10% innovation allocation from SAFe sounds reasonable on paper. In practice, it disappears. Urgent requests consume it. “We’ll experiment next sprint” becomes next PI, then never.
Structure protects experimentation from urgency. Without it, every sprint becomes reactive.
The adaptation: Every experiment starts with a written hypothesis. “We believe X will reduce Y by Z%.” No hypothesis, no experiment.
We run dedicated innovation sprints within each PI. Two sprints per PI are protected for exploration. Product support requests queue unless they’re critical. This requires leadership buy-in — someone will always argue the urgent work matters more.
We also budget explicitly for failure. Not every experiment works. That’s the point. We allocate capacity knowing some of it produces learning, not features.
Example: exploring a retrieval-augmented generation pattern for internal documentation — became a core platform feature used by five teams. Another experiment — building a custom evaluation framework — was killed after two weeks when we found an open-source tool that did it better. Both outcomes were successes. One shipped. One saved us months of wasted effort.
Innovation needs protection from urgency. Without structure, every sprint becomes reactive. The 10% allocation only works if someone defends it.
Metrics that matter
Traditional platform metrics — uptime, latency, adoption rate — still apply. But they’re insufficient for an AI platform. A model gateway with 99.9% uptime that hallucinates 10% of responses is not a healthy system.
Consider tracking these alongside traditional ones:
| Instead of only… | Also consider… |
|---|---|
| API uptime | Model quality — are responses accurate? |
| Latency p95 | Cost per successful outcome, not per API call |
| Adoption rate | Time to first agent deployed |
| Ticket volume | Agent task completion rate |
| — | How often do agents escalate or act out of bounds? |
| — | How often do guardrails trigger? |
| — | Are developers satisfied? (NPS, surveys) |
| — | Are teams self-serving or still filing tickets? |
The shift is from measuring infrastructure health to measuring outcome quality. Both matter. But if you only track the first, you’ll miss problems that users feel daily.
Measuring the wrong thing in AI creates false confidence. A 99.9% uptime means nothing if the model hallucinates 10% of responses.
Managing the culture shift
Technology changes fast. Culture changes slow. The gap between the two determines the success of a team.
Engineers comfortable with one paradigm of software development now work with another. There are engineering teams used to work on deterministic software components, need to retrain and upskill themselves to work on probabilistic AI systems. For us, used to be working on data science and PoC projects, now we are working on building an agentic AI platform. This isn’t just about skills. It’s a mental model shift.
Resistance patterns we’ve seen:
- “I don’t trust AI” — often from experienced engineers who’ve seen hype cycles before
- ”This is just hype” — sometimes correct, sometimes a defense against change
- ”I only know how to work in one way” - resistance to change, lacking growth mindset
The platform team’s role: lead by example. Dogfooding. Show value early. Don’t force adoption. Teams that adopted our platform voluntarily — because they saw a colleague ship faster — had better outcomes than teams told to adopt it. Mandated adoption creates compliance, not engagement.
This topic could be its own article. Culture change in engineering organizations during technological shifts is deep and nuanced. For now, the key insight: plan for it. Budget time for it. It won’t happen on its own.
You can deploy a platform in weeks. Changing how people think about their work takes months. Plan accordingly.
Roles and responsibilities
Traditional platform teams have clear roles: backend engineers, DevOps, SREs, product owners. An AI platform team needs those — and more.
| Role | Responsibility |
|---|---|
| AI Platform Engineer | Infrastructure + model behavior. Builds APIs and pipelines, but also understands model serving, evaluation, and prompt optimization |
| AI Safety/Governance Lead | Guardrails, behavioral boundaries, audit trails. Ensures agents act within approved limits |
| Developer Experience (DevEx) | SDKs, documentation, templates, onboarding. Makes the platform usable, not just functional |
| Tech Scout | Tracks emerging tools, protocols, and models. Rotating responsibility, not a full-time role |
| Product Owner | Prioritizes based on product team needs. Balances runway work with immediate requests |
| Scrum Master | Facilitates ceremonies, removes blockers. Now also manages the pace of change and supports team upskilling |
Two observations from building our team.
First, the (human) AI Platform Engineer is a new hybrid role. A traditional platform engineer understands infrastructure but not model behavior. An AI/ML engineer understands models but not production systems at scale. The AI Platform Engineer needs both — building reliable pipelines while also knowing when a model is underperforming or a prompt needs redesign. Finding people with both skill sets is hard. We grew ours internally — pairing platform engineers with AI engineers on real projects until the boundaries blurred.
Second, consider governance early. If agents ship before permission models are consistent, retrofitting governance becomes painful. Easier to build it in from the start than to bolt it on later.
Similar to the technology, the roles above are evolving. Especially some tasks can be completed by AI Agents themselves. It could be possible to run a platform team with AI Agents in the near future. Design for the team you need now, not the one you’ll need in the future.
New Challenges with GenAI/Agentic AI
The SAFe principles above still hold. But GenAI and Agentic AI introduce challenges that traditional platform teams never faced.
Technical unpredictability
Conventional IT platforms have reached maturity. Cloud providers offer compute, storage, and networking as commodities. You pick a provider, sign a contract, and plan your roadmap with reasonable confidence.
GenAI and Agentic AI don’t work that way. New protocols emerge monthly — MCP, A2A, and others we haven’t heard of yet. Model capabilities shift with each release. A feature you spent weeks building might become a native capability of the next model version.
In traditional platforms, you plan 1-2 PIs ahead. In GenAI, even 1 PI ahead feels like guessing. The technology moves faster than any planning cadence.
See Runway when the ground is moving for how we adapted our planning process.
Cost model disruption
Every company wants an AI platform. The question is: what should you invest in? GPUs? Talent? Subscriptions?
Traditional IT follows a depreciation model — buy hardware, amortize over 3-5 years. Cloud shifted this to subscriptions and pay-as-you-go. GenAI introduces yet another dimension: token consumption.
The difference is significant. Infrastructure usage scales linearly with users. Token consumption can scale exponentially — one agent calling another agent, each generating thousands of tokens per interaction. A single agentic workflow can consume more tokens in a minute than a chatbot does in a day.
New models release every few months, each more capable and often cheaper per token. The model you’re paying premium for today might cost a fraction in six months. But the newer model might also enable use cases that drive consumption higher.
What this means for platform teams:
- Implement token-level cost tracking from day one. Retroactively adding it is painful
- Set consumption budgets per team and per agent, with alerts before limits are hit
- Design for model portability so you can switch to cheaper alternatives without rework
- Review cost allocation monthly, not quarterly. The landscape shifts too fast for quarterly reviews
For example: One product team’s agent ran an unoptimized loop that consumed $2,000 in tokens over a weekend. We had monitoring but no alerting thresholds. Now every agent deployment includes a cost ceiling that triggers automatic throttling.
Safety and governance complexity
GenAI already raises data concerns. Corporations worry about internal documents being consumed by cloud-hosted models. Users worry about personal data becoming part of a model’s training set and surfacing in responses to others.
Agentic AI amplifies these concerns. Agents act autonomously. They make decisions, call tools, and interact with external systems — sometimes in ways their creators didn’t anticipate.
With a chatbot, a human reviews every output before it reaches the end user. With an agent, the output might be an API call, a database write, or a message to another agent. The human may not be in the loop at all.
New governance requirements for agentic platforms:
- Behavioral boundaries: What is each agent allowed to do? What tools can it access? What data can it read or modify?
- Audit trails: Every agent action must be traceable. When an agent makes a decision, you need to know why
- Circuit breakers: Automatic shutdown when an agent behaves outside expected parameters
- Human-in-the-loop checkpoints: For high-risk actions (financial transactions, data deletion, external communications), require human approval
New threat vectors also emerge with each model generation — prompt injection, jailbreaking, data exfiltration through tool calls. The attack surface of an agentic system is wider than a traditional API.
For example: We require every agent to declare its tool permissions at deployment time. An agent that needs to read a database cannot also write to it unless explicitly approved. This principle of least privilege applies to agents the same way it applies to human users.
Skill gaps
GenAI lowered the barrier for developers to integrate AI capabilities. Call an API, get a response. But the gap between “calling an API” and “building a reliable agentic system” is wider than it appears.
Prompt design, context management, agent orchestration, evaluation — these are new disciplines. They don’t map neatly to existing job titles.
AI can now write code better than most developers. The new skill isn’t writing code — it’s knowing what to build, verifying what the AI built, and designing systems at a higher level of abstraction.
The skills shifting:
| Declining value | Rising value |
|---|---|
| Syntax expertise in specific languages | System thinking across components |
| Manual coding speed | Reviewing and verifying AI-generated code |
| Framework-specific knowledge | Architecture and design judgment |
| Following established patterns | Engineering instinct for novel problems |
What this means for platform teams:
- Provide templates, examples, and starter kits — not just APIs
- Run workshops on prompt engineering, agent design patterns, and evaluation methods
- Pair platform engineers with product teams during their first agent build
- Document not just “how to use the API” but “how to build a good agent”
For example: Our first agent-building workshop had 40 attendees. Most could call our APIs within an hour. But fewer than half could build an agent that handled edge cases gracefully. The gap wasn’t technical — it was design thinking. We now include a “failure mode” exercise in every workshop: what happens when the model returns nonsense? When a tool call fails? When two agents disagree?
Conclusion
Both AI and SAFe are evolving practices. Neither has a final form.
The challenges above — unpredictability, cost, safety, skills — won’t be solved once and stay solved. New ones will emerge as the technology and our organizations evolve. The only constant is change.
This is where SAFe’s core principles matter most. Iterations. Continuous learning. Inspect and adapt. These aren’t project management rituals — they’re survival strategies for building in uncertain territory.
Agentic AI platforms are not conventional infrastructure. They host systems that make autonomous decisions. The stakes are higher and the feedback loops are shorter. Getting it right requires both technical rigor and organizational discipline.
In 2016, I attended the International Supercomputing Conference (ISC) in Frankfurt, Germany. I listened to Andrew Ng talking about how he set up the data science platform team at Baidu. Ten years later, it was him again — this time talking about agentic AI. The technology changed. The principles of building a platform to support the development and deployment of AI applications, however, remained the same.
